Для кого этот курс?
Курс разработан для специалистов и руководителей разного профиля.
AI-инженеров
Глубокое погружение в техническую реализацию, освоение паттернов проектирования и отладку сложных агентов.
Data Scientists
Практические навыки по интеграции LLM с корпоративными данными, RAG, графами и агентными системами.
Менеджеров по ИИ
Понимание архитектурных компромиссов, бизнес-ценности различных подходов и стратегий масштабирования.
IT-руководителей
Формирование видения по созданию enterprise-решений и планированию дорожной карты развития AI-продуктов.
Ключевые результаты обучения
Что вы получите по итогам курса
Готовая рабочая среда
Настроенное локальное окружение с LLM, векторной базой данных и инструментами разработки.
Портфолио проектов
Реализованные RAG-системы, графы знаний и многофункциональные агенты на основе корпоративных данных.
Стратегическое видение
Понимание, как выбрать архитектуру для бизнес-задачи и спланировать дорожную карту развития AI-продукта.
Production-ready навыки
Знания о мониторинге, управлении состоянием и обработке ошибок в сложных AI-системах.
Стек технологий
Работаем только с on-premise решениями для максимального контроля.
Программа курса
Детальный 8-часовой практический интенсив.
Развертывание и настройка полного on-premise стека. Сравнение фреймворков для запуска LLM и выбор оптимального решения для разработки и production.
Теория (15 мин):
- Почему on-premise: безопасность данных, контроль затрат, кастомизация и независимость от внешних провайдеров.
- Обзор локальных LLM: Сравнение моделей. Qwen-2.5 как оптимальный выбор по балансу производительности, качества и размера для enterprise-задач.
- Сравнение фреймворков: Ollama (прототипирование), vLLM (высокая пропускная способность в production) и SGLang (рекордная скорость для сложных промптов и RAG).
Практика (45 мин):
- Развертывание стека через
docker-compose. - Загрузка и тестовые прогоны моделей (Qwen, Llama) через CLI и API.

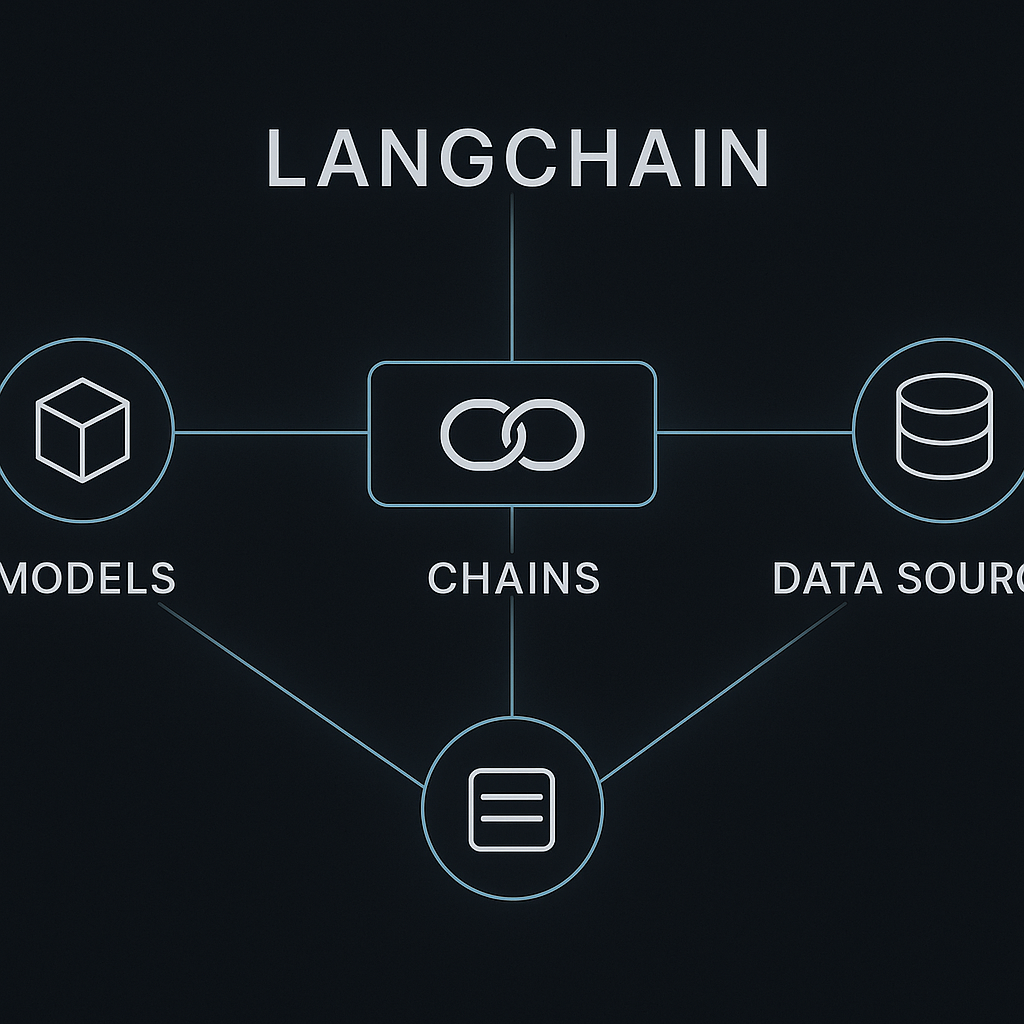
Изучение архитектуры LangChain для on-premise решений, создание первых цепочек и работа со структурированным выводом для надежных систем.
Теория (15 мин):
- Архитектура LangChain для on-premise: перенаправление на локальные эндпоинты.
- LangChain Expression Language (LCEL): Декларативный способ построения AI-систем с поддержкой streaming, async и параллелизма.
- Структурированный вывод с Pydantic для предсказуемого и валидного JSON.
Практика (45 мин):
- Подключение к локальной LLM через
ChatOllama. - Создание первой LCEL-цепочки.
- Парсинг вывода в JSON/Pydantic.
- Работа с мультимодальной моделью (LLaVA) для анализа изображений.
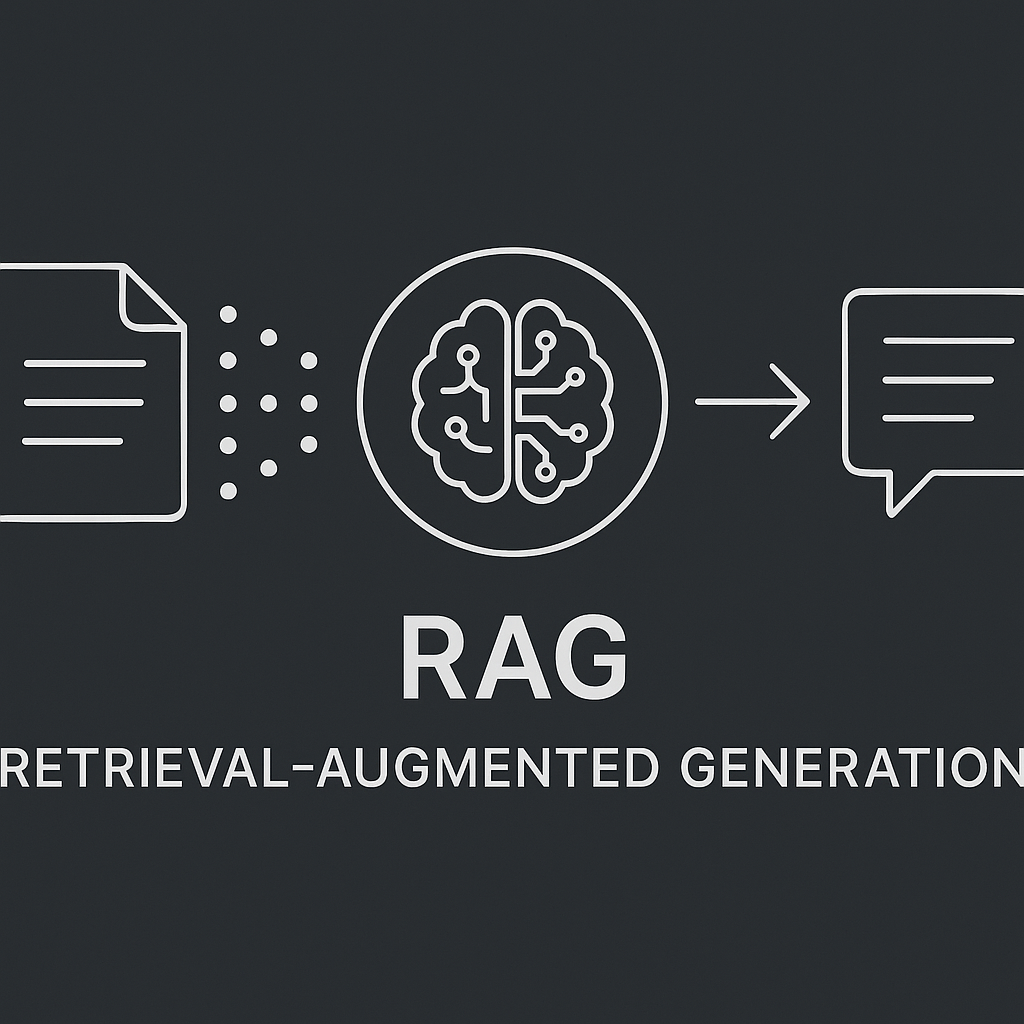
Создание RAG-системы на корпоративных данных. Изучение векторного, полнотекстового и гибридного поиска с фокусом на enterprise-решения.
Теория (20 мин):
- Введение в Retrieval-Augmented Generation (RAG).
- Векторный поиск: от прототипирования с ChromaDB до enterprise-grade решений на Qdrant (производительность на Rust) и Milvus (масштабируемость для миллиардов векторов).
- Полнотекстовый поиск (BM25) для поиска по ключевым словам.
- Гибридный поиск: комбинация подходов для максимальной релевантности.
Практика (70 мин):
- Загрузка и чанкинг корпоративных документов.
- Создание векторной базы в ChromaDB для прототипа.
- Сборка RAG-цепочки с помощью LCEL.
- Реализация гибридного поиска с
EnsembleRetriever.
Интеграция графов знаний для получения точных, структурированных фактов из текста и дополнения RAG-систем для ответов на сложные вопросы.
Теория (15 мин):
- Что такое графы знаний и как они дополняют RAG, давая точные факты, а не фрагменты текста.
- Извлечение троек (субъект-предикат-объект) из текста с помощью LLM.
Практика (45 мин):
- Создание цепочки для извлечения троек.
- Построение и визуализация графа с помощью
NetworkX. - Создание кастомного ретривера для поиска по графу.

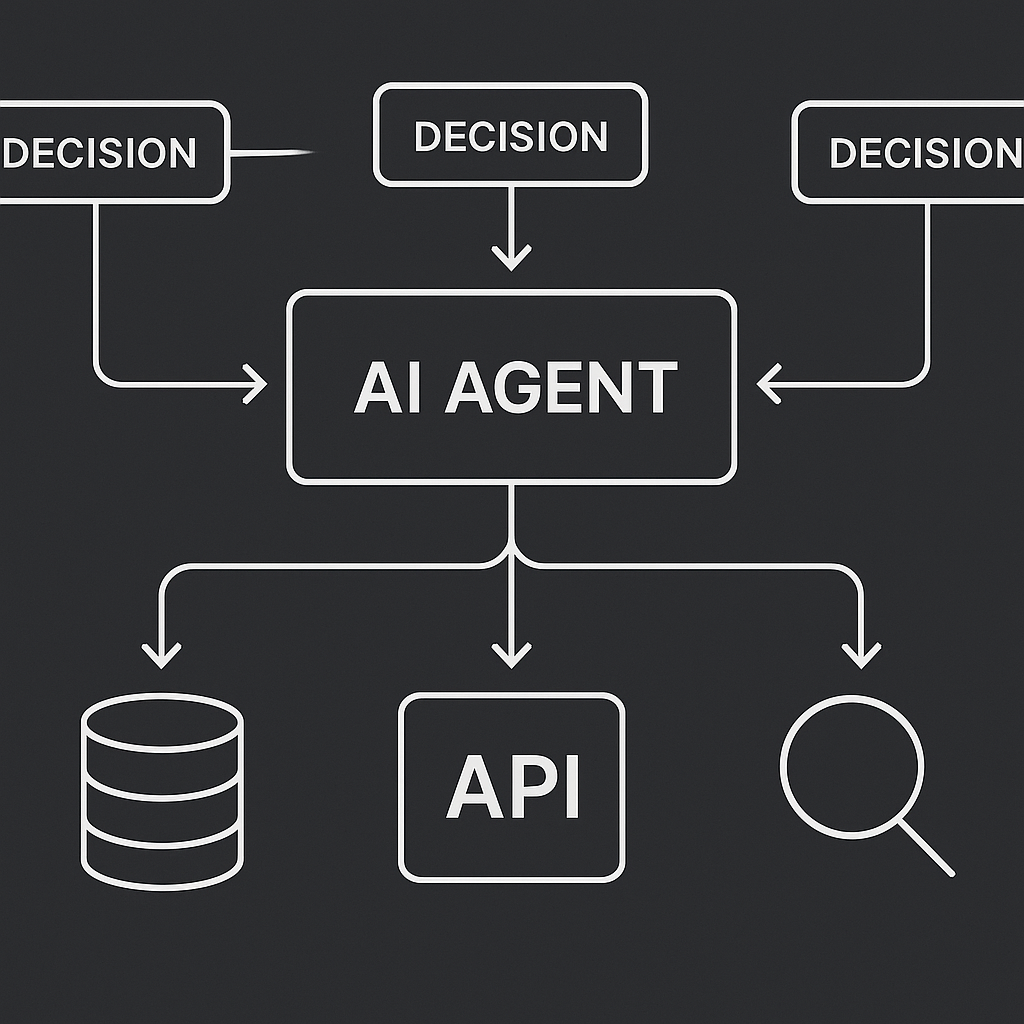
Переход от простых цепочек к динамическим агентам. Проектирование сложных workflow, управление множеством инструментов и роутинг.
Теория (25 мин):
- Отличие агентов от цепочек: динамическое принятие решений.
- Архитектура LangGraph: State, Nodes, Edges.
- Механизм
Tool Callingдля вызова внешних функций.
Практика (95 мин):
- Создание кастомных инструментов.
- Построение графа состояний в LangGraph.
- Реализация условного роутинга для ветвления логики.
- Стратегия для 20+ инструментов: разработка агента-роутера с двухуровневой логикой (категоризация -> выбор инструмента).
Работа с ограничениями LLM, такими как конечное контекстное окно, и реализация отказоустойчивых стратегий.
Теория (15 мин):
- Проблема ограниченного контекста.
- Стратегии: Сжатие истории диалога, Sliding Window, явная суммаризация.
Практика (45 мин):
- Реализация логики сжатия истории диалога в явном виде в стейте LangGraph.
- Применение
Sliding Windowдля простых случаев. - Создание
Fallbackмеханизма на основе счетчика рекурсии для обработки зацикливаний и ошибок агента.

Основы вывода AI-систем в production: логирование, метрики и создание простого пользовательского интерфейса.
Теория (5 мин):
- Ключевые метрики: Latency, Accuracy, Token Usage.
- Важность логирования и трассировки вызовов для отладки.
Практика (25 мин):
- Создание простого, но функционального UI с
Gradio. - Добавление
callbacksдля логирования шагов выполнения агента в консоль (прототип для ELK/Datadog).
Дополнительные материалы
Все, что нужно для быстрого старта и дальнейшего развития.
Готовый `docker-compose`
Запустите все необходимое окружение (Ollama, ChromaDB, Jupyter) одной командой для быстрого старта.
Чек-лист для самоизучения
Подробный список тем для дальнейшего углубления: fine-tuning, продвинутые RAG-стратегии, оценка качества и безопасность.
Roadmap от MVP до Enterprise
Пошаговый план эволюции AI-проекта: от локального чат-бота до масштабируемой мульти-агентной платформы.